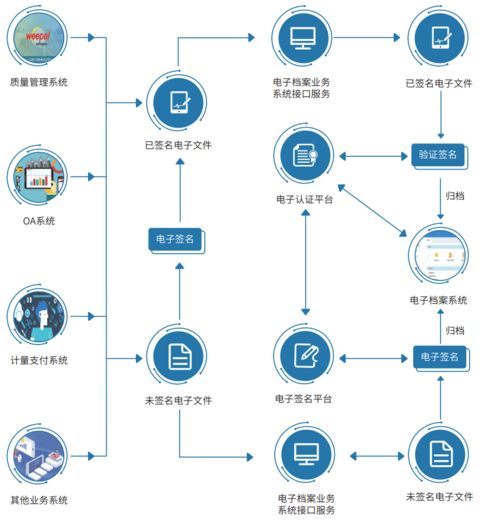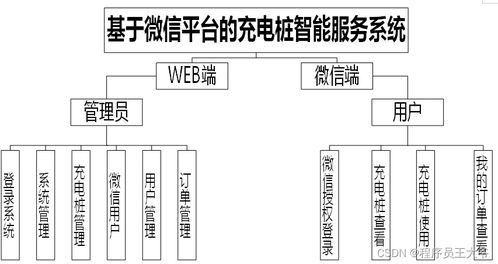
在當今數(shù)字化時代,企業(yè)核心業(yè)務系統(tǒng)正加速向微服務架構演進,以追求更高的敏捷性、可擴展性與技術異構能力。隨著服務數(shù)量呈指數(shù)級增長、依賴關系日益復雜,傳統(tǒng)的單體監(jiān)控手段已捉襟見肘。一套面向商業(yè)大規(guī)模微服務環(huán)境的分布式監(jiān)控系統(tǒng),已成為現(xiàn)代信息系統(tǒng)運行維護服務不可或缺的核心支柱,它不僅是故障的“預警雷達”,更是保障業(yè)務連續(xù)性、優(yōu)化系統(tǒng)性能與驅動決策的數(shù)據(jù)中樞。
一、 大規(guī)模微服務監(jiān)控的獨特挑戰(zhàn)與核心需求
微服務架構將單體應用拆分為數(shù)十、數(shù)百甚至上千個獨立部署、松耦合的服務。這種架構在帶來靈活性的也引入了顯著的運維復雜度:
- 海量與動態(tài)性:監(jiān)控對象(實例、容器、節(jié)點)數(shù)量龐大且生命周期短暫,自動擴縮容、滾動更新成為常態(tài)。
- 拓撲復雜性:一次用戶請求可能穿越多個服務,形成復雜的調用鏈。故障定位需要清晰的拓撲視圖與鏈路追蹤。
- 指標多樣性:需要采集基礎設施(CPU、內存、網(wǎng)絡)、中間件(數(shù)據(jù)庫、消息隊列)、應用業(yè)務(每秒交易數(shù)、錯誤率、自定義指標)等多維度數(shù)據(jù)。
- 數(shù)據(jù)關聯(lián)性:孤立地看某個服務的指標意義有限,必須能將鏈路、日志、指標、事件進行關聯(lián)分析,才能快速定位根因。
因此,一個合格的分布式監(jiān)控系統(tǒng)必須滿足:全棧可觀測性、實時性與高性能、智能分析與預警以及高可用與自愈能力。
二、 分布式監(jiān)控系統(tǒng)的核心架構層次
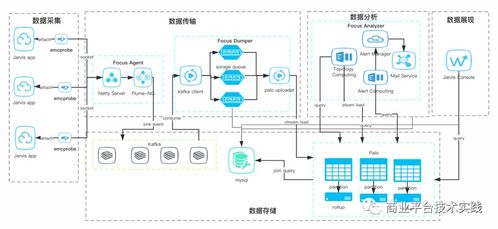
一個成熟的商業(yè)級系統(tǒng)通常采用分層、解耦的架構設計:
- 數(shù)據(jù)采集層(Agent/Exporter):
- 輕量級代理廣泛部署于每個服務實例或主機,負責收集指標(Metrics)、追蹤鏈路(Traces)和抓取日志(Logs)。常用技術如Prometheus Exporter、OpenTelemetry SDK、Filebeat等。
- 關鍵要求是低開銷、標準化(如OTLP協(xié)議)和靈活的配置能力。
- 數(shù)據(jù)傳輸與緩沖層:
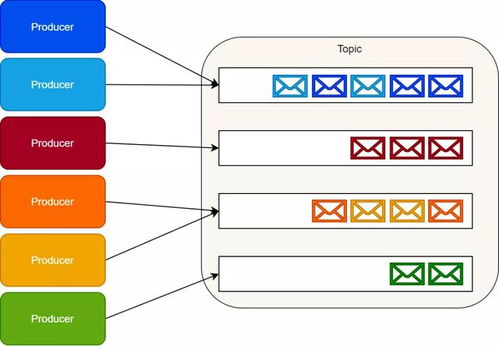
- 處理海量數(shù)據(jù)流,提供緩沖、路由和初步過濾。消息隊列(如Kafka、Pulsar)或流處理平臺在此層扮演關鍵角色,確保數(shù)據(jù)在高峰期的可靠傳輸與后端解耦。
- 數(shù)據(jù)存儲與計算層:
- 時序數(shù)據(jù)庫(如Prometheus TSDB、VictoriaMetrics、InfluxDB、TDengine)高效存儲和查詢指標數(shù)據(jù)。
- 分布式追蹤存儲(如Jaeger、Zipkin后端)存儲調用鏈數(shù)據(jù)。
- 日志索引與存儲(如Elasticsearch、Loki)提供全文檢索與聚合分析。
- 越來越多的系統(tǒng)采用數(shù)據(jù)湖或統(tǒng)一存儲概念,試圖用單一平臺(如Apache Doris、ClickHouse)處理可觀測性三大支柱,以簡化架構并增強關聯(lián)分析能力。
- 分析、告警與可視化層:
- 可視化:通過Grafana、商業(yè)BI工具等創(chuàng)建動態(tài)儀表盤,直觀展示系統(tǒng)健康狀態(tài)、業(yè)務KPI及關聯(lián)視圖。
- 告警管理:基于靈活規(guī)則(閾值、同比環(huán)比、機器學習異常檢測)產(chǎn)生告警,并通過分級、降噪、聚合后,通過多渠道(釘釘、微信、短信、電話)通知運維人員。平臺需具備完整的告警生命周期管理(產(chǎn)生、確認、升級、解決、復盤)。
- 智能分析:集成AIOps能力,實現(xiàn)異常自動檢測、根因分析、故障預測與智能止損建議。
- 統(tǒng)一管控與API層:
- 提供配置管理、權限控制、審計日志、服務發(fā)現(xiàn)集成等管控功能。
- 開放的API是實現(xiàn)監(jiān)控即代碼(Monitoring as Code)、與CI/CD流水線及ITSM系統(tǒng)(如ServiceNow)集成的關鍵。
三、 信息系統(tǒng)運行維護服務中的關鍵實踐
將監(jiān)控系統(tǒng)深度融入運維服務體系,才能最大化其價值:
- 建立服務健康度綜合模型:不僅監(jiān)控技術指標,更要將業(yè)務指標(如訂單成功率、支付延遲)納入健康度評估,定義清晰的SLA/SLO/SLI,并實現(xiàn)自動化巡檢與報告。
- 實現(xiàn)告警閉環(huán)管理:將告警與事件管理、故障響應流程(Playbook)無縫對接。利用監(jiān)控數(shù)據(jù)自動創(chuàng)建工單、觸發(fā)應急會議,并在故障解決后自動生成復盤報告,推動系統(tǒng)改進。
- 容量規(guī)劃與性能優(yōu)化:基于歷史監(jiān)控數(shù)據(jù)趨勢分析,預測資源需求,指導容量擴容。通過鏈路分析與性能剖析,持續(xù)識別性能瓶頸并優(yōu)化代碼與架構。
- 推動DevOps與SRE文化:監(jiān)控數(shù)據(jù)應對開發(fā)團隊透明,推動建立錯誤預算(Error Budget)機制,促進開發(fā)與運維共同對系統(tǒng)穩(wěn)定性和用戶體驗負責。
- 保障監(jiān)控系統(tǒng)自身的高可用:監(jiān)控系統(tǒng)自身必須是分布式、高可用的,避免成為單點故障。通常需要跨可用區(qū)部署,并設置對監(jiān)控系統(tǒng)的“元監(jiān)控”。
四、 未來發(fā)展趨勢
未來的商業(yè)監(jiān)控系統(tǒng)將更加強調:
- 云原生與Serverless原生:更好地支持Kubernetes、Service Mesh和無服務器架構。
- AIOps深度集成:從被動告警轉向主動預測與自治修復。
- 可觀測性驅動開發(fā):在軟件開發(fā)初期即嵌入可觀測性代碼,實現(xiàn)“可觀測性左移”。
- 成本關聯(lián)分析:將資源消耗、性能指標與云成本關聯(lián),實現(xiàn)“FinOps”可視化。
###
構建并運營一個面向商業(yè)大規(guī)模微服務的分布式監(jiān)控系統(tǒng),是一項復雜的系統(tǒng)工程,它遠不止是工具的堆砌。成功的核心在于以終為始,緊密圍繞業(yè)務目標,構建覆蓋數(shù)據(jù)采集、傳輸、存儲、分析與行動的完整閉環(huán),并將其深度融入企業(yè)信息系統(tǒng)運行維護的流程與文化中。只有這樣,才能在微服務的復雜迷宮中點亮明燈,確保數(shù)字業(yè)務的穩(wěn)定、高效與持續(xù)創(chuàng)新。